
Simanaitis Says
On cars, old, new and future; science & technology; vintage airplanes, computer flight simulation of them; Sherlockiana; our English language; travel; and other stuff
ALGORITHMS REDUX PART 2
YESTERDAY, WE STARTED gleaning tidbits from BBC World Service’s “The Forum” and its September 16, 2021, presentation of “Algorithms: From the Ancients to the Internet.” For this forum, the BBC’s Bridget Kendall assembled a trio of specialists, Dr. Ramesh Srinivasen, Dr. Aurélie Jean, and Professor Emeritus Ian Stewart.
Yesterday’s Part 1 concluded with discussion of the greedy algorithm, which seeks local, as opposed to global, solutions. Today we learn about the bubble sort algorithm and how a wealth of data and powerful computers are encouraging another approach: brute force.
Pair-wise Solutions. A bubble sort algorithm is related to locally-acting greedy approaches, in that it compares adjacent elements, leaves them alone if appropriate, or swaps them if they’re in the wrong order. Iteration follows.
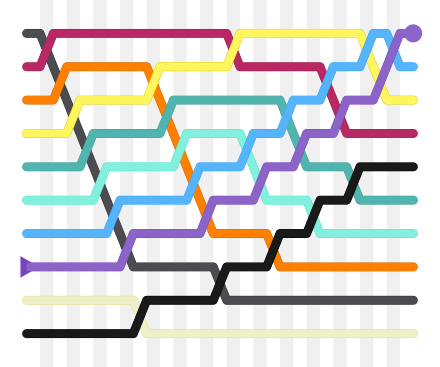
Professor Stewart leads Bridget through a sorting of six playing cards, randomly selected 5, 3, 6, 4, ace, 2: “Look at the first pair; are they in the right order? No, so swap them around. Then look at the [new] second pair, 5,6. Are they in the right order? Yes. Then move on to the next pair, 6,4,” and so on through the list. Take the new order and reapply. Then repeat until the entire set meets the correct criterion.
“It’s called the bubble sort,” Professor Stewart says, “because the biggest number bubbles its way through until it gets to the top and, once it’s there it just sits there. And then you do it again and again.”
Unlike more efficient sorting algorithms, the bubble sort’s chief disadvantage is its redundancy.
Brute-force Algorithms. In a sense, the other extreme to greedy and bubble sort are the brute-force algorithms. Wikipedia writes that brute force “consists of systematically enumerating all possible candidates for the solution and checking whether each candidate satisfies the problem’s statement.”

A brute-force search gets the job done—eventually. However, solution domains may be so large that this approach is impractical.
Data-Rich, Computer-Rich. On the other hand, technology has evolved to be compatible with brute-force algorithms. Our society is data-rich, even, some say, to our own detriment. And our computers have grown larger and quicker.
A.I. Meets Al’Khwarizmi. Both of these trends are enhancing Artificial Intelligence and machine learning. “Yes,” Professor Stewart says, “this has had some very important applications in things like language translation, and a very recent one is protein folding. This is very, very important for all sorts of medical and other applications, and there have been some spectacular advances using these deep networks.”
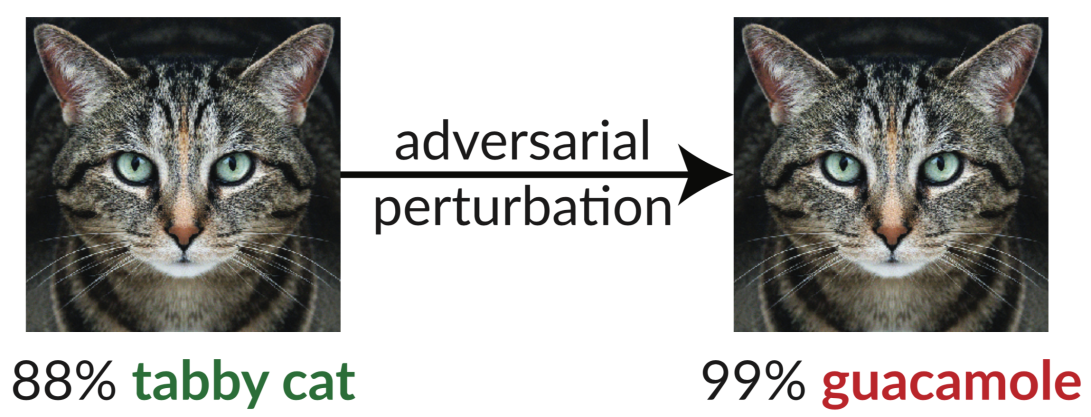
Fooling the Machine. “But,” Professor Stewart notes, “it’s also possible to fool these networks if you really want to.” He mentions the cat/guacamole recognition problem cited here at SimanaitisSays.
Also Dr. Jean notes that diversity of data is necessary to avoid biased machine learning, as exemplified by studies revealing flawed recognition of people of color.
A Digital Bill of Rights. Bridget asks Dr. Srinivasen whether we need algorithmic oversight. “Absolutely we do,” he says, “Especially algorithms that are going to scale to large numbers of users. I have written a few pieces for the mainstream media calling for what I call a Digital Bill of Rights. I’ve been working on policy issues around these themes. So we need disclosure and transparency around data being collected. We need to know what algorithms are being used to influence what we see.”
Excellent food for thought. I thank Bridget for bringing these specialists together for a most interesting Forum. ds
© Dennis Simanaitis, SimanaitisSays.com, 2021
