
Simanaitis Says
On cars, old, new and future; science & technology; vintage airplanes, computer flight simulation of them; Sherlockiana; our English language; travel; and other stuff
FACING UP TO IT
“DID HE really say that??” Maybe yes, maybe no. Facial video manipulation is technically fascinating, potentially beneficial and yet terrifying. The concept builds on human sensitivity to red, green and blue. It could lead to seamless, real-time video translations. Yet the technology could also destroy any apparent veracity of video documentation.
The concept is described and demonstrated in Face2Face: Real-time Face Capture and Reenactment of RGB Videos by researchers at the University of Erlangen-Nuremberg, Max-Planck-Institute for Informatics and Stanford. I thank Ray DeTournay for bringing this latest research to my attention. It’s a further development of facial recognition, touched on a while back at SimanaitisSays in “I Recognize That!—Good or Bad?”

A video source can be digitized, allowing another to be rendered with a similar expression. This and other images from Face2Face.
Gmax gives a flavor of the basic technique. A computer image of a face is subdivided into tiny segments, each manipulated to achieve a grin, grimace or expression of indifference. Researchers took as their starting point monocular RGB (Red/Green/Blue) images of a face. Its monocular nature implies two-dimensional imagery, as opposed to a more-computer-intensive three-dimensionality. It’s also what’s perceived in a video source, which, like our color vision, is RGB-based.

Additive color mixing: Red, green and blue light in equal intensities yields white. Image from en:User:Bb3cxv.
Humans, together with most other primates, are trichromats. That is, we identify color through ocular receptors sensitive to three hues. This isn’t unique in the animal kingdom. Dogs and some other mammals are dichromats; bird and fish, quadrachromats. Many insects are trichromats, but with sensitivities beyond the human range into the ultraviolet.

The general idea: A source expression gets transferred to a target.
The source and target faces are both in RGB video format. The inset color image shows the target’s original neutral expression. Each face is digitized, the gray one on the left capturing the source’s expression in real time. The gray one on the right has a corresponding modification and is given its RGB rendering as output video, lagging by only three frames
High-end TVs have a refresh rate of 120 frames per second. Movie projectors run at 24 fps with technology that yields a refresh rate of two or three times this. Thus the Face2Face three-frame delay is perceived as essentially real-time.
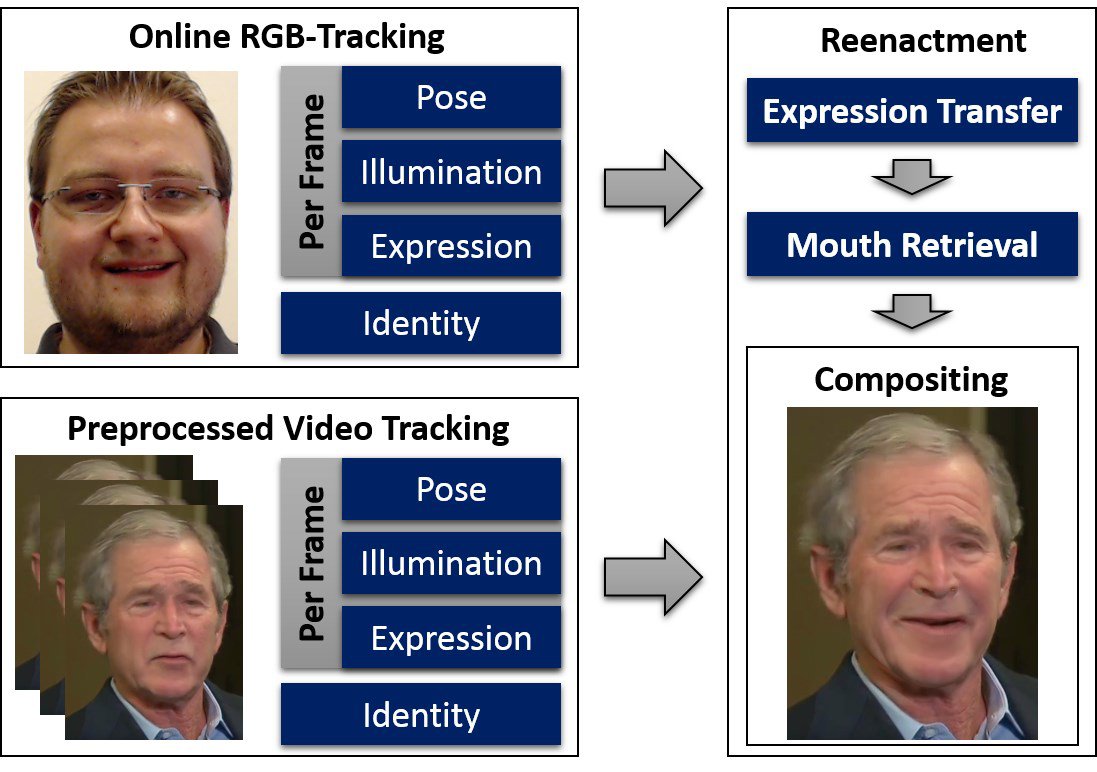
Method overview.
The researchers’ technique tracks the source actor’s image with a webcam. It treats this and the target video to processing on a frame-by-frame basis. The source’s expression is transferred, together with fine-tuning of the target’s mouth. This last technique, what the researchers call Mouth Retrieval, is seen as particularly important in synthesizing a realistic expression.

Mouth Retrieval.
The researchers’ technique for Mouth Retrieval uses a sequence of target mouth frames rather than copying the source mouth region or using generic representations of teeth. It is one of the more innovative aspects of their research.

A selection of expressions, source and original inset, and otherwise.
The researchers’ video demonstration is uncanny in its verisimilitude. A scary aspect is in the technology’s capability of doctoring a benign video into another that’s decidedly less so. This is especially worrisome, given the apparent gullibility of “seeing it on the Internet—and thus it must be true.”
The researchers note that their approach is the first real-time facial reenactment system that requires just monocular RGB input. One potential benefit they envision is enhanced real-time videos with translated audio: A webcam would capture the translator’s facial movements. The system would dub the target’s audio to match the translation, with a video wrapping the target’s mouth around the translated words.
Spaghetti westerns of the mid-1960s would lose part of their charm. ds
© Dennis Simanaitis, SimanaitisSays.com, 2016
