
Simanaitis Says
On cars, old, new and future; science & technology; vintage airplanes, computer flight simulation of them; Sherlockiana; our English language; travel; and other stuff
SAY AGAIN, PLEASE, SYNTHETICALLY IF YOU LIKE
AMONG VOICES I might recognize are those of HAL 9000, Siri, Stephen Hawking, our Honda’s nav system, IBM “Jeopardy!” Watson and the Tokyo Subway’s Elmer Fudd. All are examples of voice synthesis, the interface of computers and humans.

IBM researcher Michael Picheny looks at sound patterns of synthesized speech. Image from The New York Times, February 14, 2016.
“Creating a Computer Voice That People Like,” by John Markoff, appeared in the February 14, 2016, edition of The New York Times. This article got me researching computerized speech in general. It describes how researchers at IBM’s Watson Multimodal Lab have studied speech synthesis, with an ear toward making it acceptable to us humans.
An important aspect of their research is balancing between the metallic robotic voice that we associate with early efforts of synthesized speech with plu perfect renderings of computer-speak that many find unnerving, if not downright creepy.

2001: A Space Odyssey, 1968, MGM, Stanley Kubrick, screenplay, producer, director.
As an example of the latter, I recall HAL 9000, the Heuristically programmed ALgorithmic computer interacting with astronaut Dave Bowman in 2001: A Space Odyssey. Canadian actor Douglas Rain provided Hal 9000’s chillingly unemotional chatter. Yet its prosaic robospeak in the film was all the more memorable, especially when Hal experienced his final deactivation.
I remember the oddity of Elmer Fudd announcing stops on the Tokyo Subway, traceable, no doubt, to the subway’s less than hi-fi sound system. I suspect the Japanese person recording all the various destinations has a completely natural voice in real life.
Siri, introduced in Apple’s iPhone 4S in 2011, is another synthesized voice. In real life she’s Susan Bennett, whose other vocal artistry includes the First National Bank of Atlanta’s “Tillie the All-Time Teller,” public address announcements in Delta Air Lines terminals around the world and in GPS nav systems.

Susan Bennett, Siri 1, chats with the “real” Siri. Image from susancbennett.com.
These are examples of speech concatenation. For example, Susan Bennett spent the month of July 2005, four hours a day, reading phrases and sentences. These snippets are then reformed into sentences and paragraphs of Siri’s responses. Apple hadn’t formally acknowledged Siri’s personage. However, CNN hired audio-forensics experts who were confident as to her identity.
Back in 1993, a group called the Barbie Liberation Organization got involved in a bit of voice skullduggery. It all started when Mattel’s Teen Talk Barbie uttered stereotypical chatter such as “Math class is tough.” The BLO responded by swapping Barbie voice boxes with those of Mattel’s combat-ready G.I. Joe.

Barbie and her pal G.I. Joe. A news report describes their involvement with the BLO.
Undisclosed numbers of Barbies and G.I. Joes were liberated from toy shelves, given a cultural update and then returned to the shops. G.I. Joe now chirped, "Wanna go shopping?" and "The beach is the place for the summer." Barbie responded, “Vengeance is mine” and "Dead men tell no tales."
A noted voice synthesis came with IBM’s Watson, designed to play the answer/question game “Jeopardy!” In 2011, Watson beat two former winners of the TV game. Since then, he has found employment in assessing utilization management at Memorial Sloan Kettering Cancer Center. Not that he needs the job; Watson garnered $1 million for his “Jeopardy!” victory.

Watson, IBM's "Jeopardy!" winner.
Watson has four terabytes of stored information, some 200 million pages of content. (By comparison, my iMac/PC has a 1-terabyte memory.) Watson uses a speech-to-text algorithm to translate the “Jeopardy!” answer into digital form, which gets analyzed based on his stored data. Then a text-to-speech algorithm forms Watson’s response, his voice synthesized from recordings of actor Jeff Woodman.

An example of a text-to-speech algorithm. Image by Andy0101.
Stephen Hawking, theoretical physicist (and occasional guest star on “The Big Bang Theory”), also uses voice synthesis. Hawking suffers from a slowly progressing form of amyotrophic lateral sclerosis which is gradually paralyzing him. These days, he communicates using a single cheek muscle linked to a speech synthesizer.
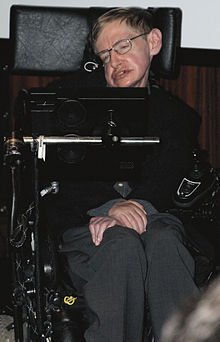
The efficiency of Stephen Hawking’s synthesized speech has been improved by a team of researchers from Intel.
Hawking’s latest interface is called ACAT, for Assistive Contextually Aware Toolkit. By including many of his previous documents into memory, the toolkit provides shortcuts to intended words or phrases based on earlier usage.
As a last example of human speech nuances, researchers at the University of Portsmouth, England, have studied the underlying emotional content of a smile. Amy Drahota and her colleagues analyzed video-taped interviews of people who were asked a series of questions that might have elicited a smiling reaction.
In “The Vocal Communication of Different Kinds of Smile,” Speech Communication, 2007, these researchers focused on four types: The Duchenne smile is the most honest and intense. A second type has the Duchenne appearance but without emphatic eye reaction. The third category is a suppressed smile; the fourth, no smile at all.
Then researchers played only the audio portion of interviews to other test subjects. These listeners were able to identify the different smiles even sans video confirmation. Noted Amy Drahota, “It’s possible that we interpret these ‘flavours’ in someone’s voice almost without noticing.”
In similar fashion, I know that HAL 9000 wasn’t smiling at all when he sang “Bicycle Built for Two.” ds
© Dennis Simanaitis, SimanaitisSays.com, 2016
i

Is it common knowledge that the name HAL came from the preceding letters for IBM, to protect the innocent maybe?
Interesting. This is the first I heard it.
I cited the “Heuristically…” description, part of standard lore.
This was in Slate a few years back. Still very much a theory, I think your take on it as “heuristic and algorithmic” is more likely.
http://www.slate.com/blogs/browbeat/2013/01/07/hal_9000_ibm_theory_stanley_kubrick_letters_shed_new_light_on_old_debate.html