
Simanaitis Says
On cars, old, new and future; science & technology; vintage airplanes, computer flight simulation of them; Sherlockiana; our English language; travel; and other stuff
A.I.’S PLACE, HUMAN EFFORT, AND FRICTION-MAXXING PART 1
HUMANITY IS AT A CUSP OF INTELLECT, tantamount to moveable type’s effect on sharing thought, radio and television’s effect on communicating it, and the computer’s effect on amassing it. Today, artificial intelligence may be finessing humans out of the process.
Is this inevitable? Beneficial? Detrimental? Or, perhaps most important, controllable?
Several articles are ripe for gleaning tidbits which follow here in Parts 1 and 2 today and tomorrow.

The Scaling of A.I. Donald MacKenzie has appeared here at SimanaitisSays before: See “Lasers Over Mahwah,” November 16, 2014; “Making (Or Losing) Zillions At (Almost) The Speed of Light,” March 21, 2019; and “Googling—For Fun and Profit,” November 29, 2025. Today, MacKenzie addresses “AI’s Scale” in London Review of Books, February 5, 2026. He observes, “The imperative to increase scale is deeply embedded in the culture of AI.”
This imperative, I suspect, is partly technical—and partly corporate greed.
MacKenzie cites, “Hyperion is the name that Meta has chosen for a huge AI data centre it is building in Louisiana. In July, a striking image circulated on social media of Hyperion’s footprint superimposed on an aerial view of Manhattan. It covered a huge expanse of the island, from the East River to the Hudson, from Soho to the uptown edge of Central Park.” That is, half the area of Manhattan devoted to a single facility.
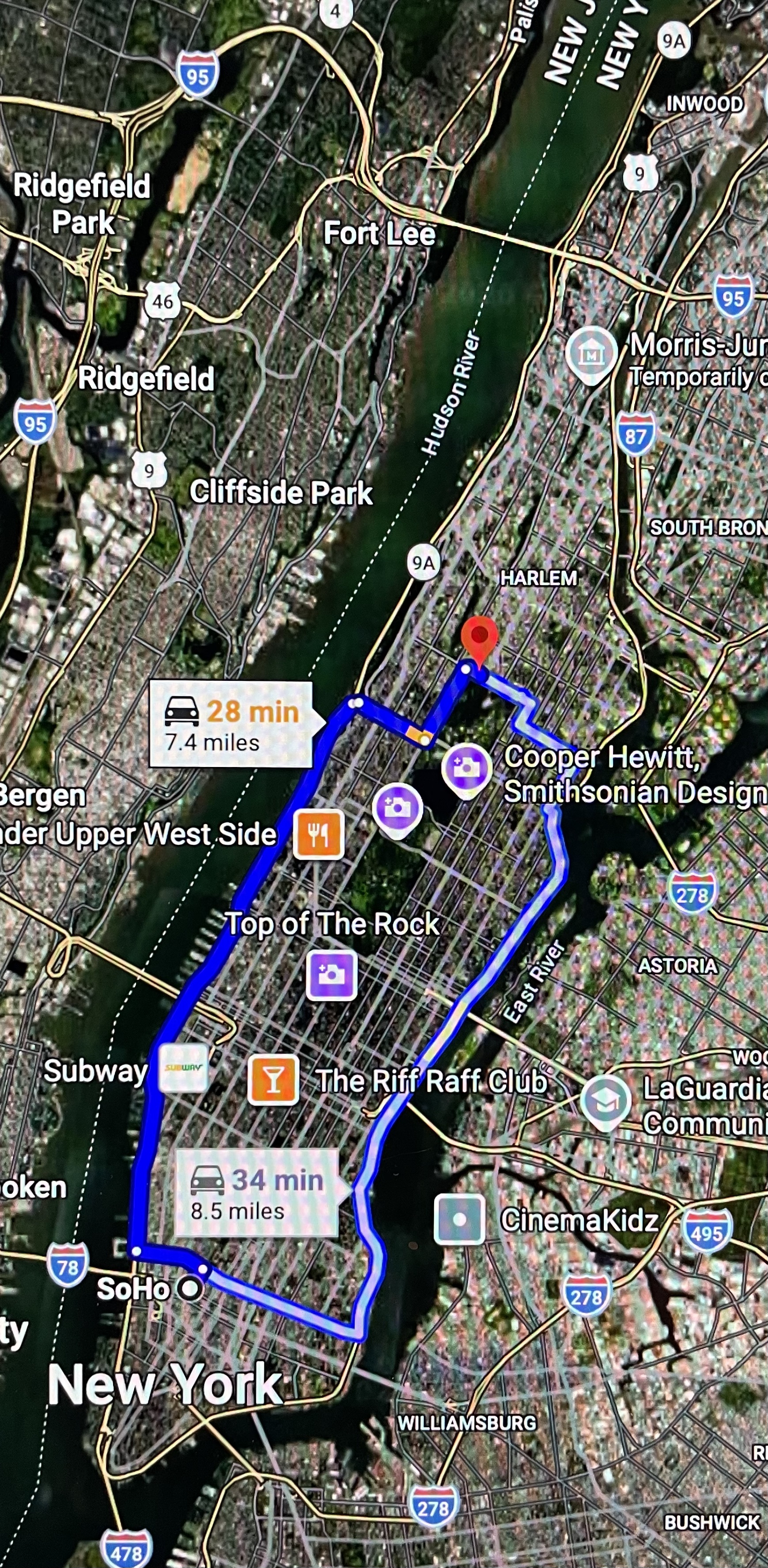
Image from Google Maps.
In another comparison, MacKenzie notes, “In August, researchers for Morgan Stanley estimated that $2.9 trillion will be spent globally on data centres between 2025 and 2028, while Citigroup has estimated total AI investment globally of $7.8 trillion between 2025 and 2030. (For comparison, the US defence budget is currently around $1 trillion per year.)”
And in another, he recounts, “The graphics chips and data centres on which ‘arbitrary amounts’ are being spent require huge quantities of electricity to power them. Some of this is coming from renewable sources, but much of it involves burning natural gas or sometimes even coal. Just one of the many new gas-fired power plants that are being constructed in the U.S. to meet the growing demands of data centres is on the site of an old coal-fired power station near Homer City, Pennsylvania. When it is up and running it will generate 4.4 gigawatts, just a little more than the peak winter electricity demand for the whole of Scotland.”
Environmental Concerns. MacKenzie cites, “The International Energy Agency reckons that if the current global expansion of data centres continues, the CO2 emissions for which they are responsible, currently around 200 million tonnes per year, will be about 60 per cent higher by 2030.”
“In a rational world,” MacKenzie posits, “new AI data centres would be built only where ample renewable electricity is available to power them. But in a reckless race along the diminishing-returns curve, whatever fuel is immediately available will tend to get used. In the US, that still mostly means natural gas; in China, it’s coal.”
Hardly the idyllic setting for upscaling A.I.
Bigger May Be Better—But By How Much?
“The more resources you put in,” MacKenzie writes, “the better the results, but the rate of improvement steadily diminishes.” He cites a post from a pro-upscaling Sam Altman that “the intelligence of an AI model roughly equals the log of the resources used to train and run it.” That is, it’s not a linear function, but a logarithmic one.
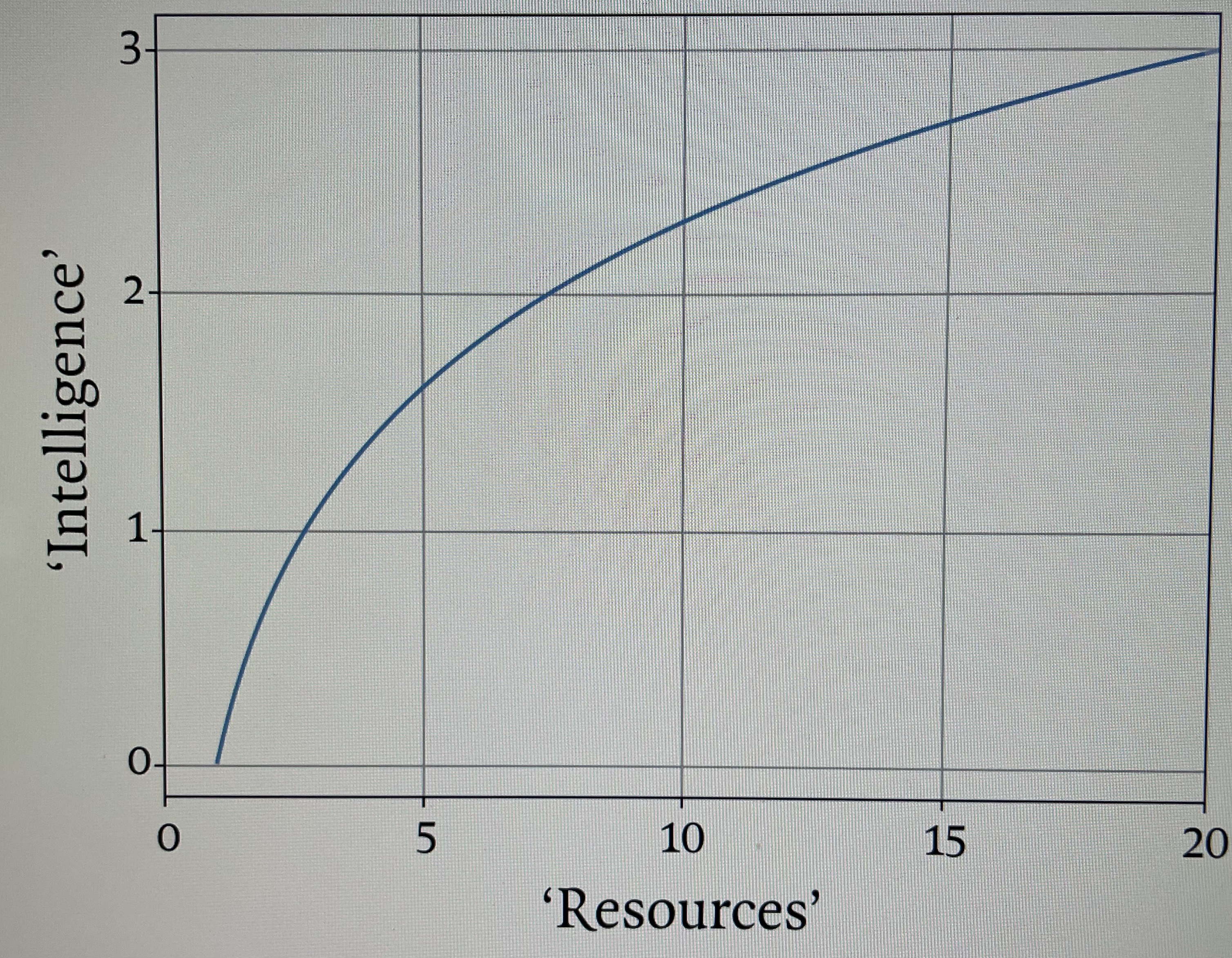
A familiar logarithmic curve. Image from LRB.
And Whence the Data? Recall that the intelligence of a Large Language Model comes from scraping the Internet for data, then performing probabilistic “next word” algorithms. MacKenzie observes that there’s already a constraint on human-produced data; he cites OpenAI co-founder Ilya Sutskever’s observation that “we have but one internet … data is the fossil fuel of AI.”
And to feed the process A.I.-generated data only diminish probabilistic accuracy by virtue of less-than-reliable input.
The Maltese Quandary. MacKenzie recounts, “Another researcher I have spoken to, Lonneke van der Plas, who is a specialist in natural language processing, implicitly warns of the risk of training AI models on computer-generated data. Among the languages on which she works is Maltese, which has only around half a million native speakers. Much digitally available Maltese, she tells me, is low-quality machine translation. In consequence, she says, if you go all out for scale in developing a model of Maltese ‘you get a much worse system than if you carefully select the data’ and exclude the reams of poor-quality text.”
Recall GIGO: Garbage In, Garbage Out.
Tomorrow in Part 2, we’ll discuss two means of controlling this quandary: the 30% A.I. Rule and Friction-Maxxing. ds
© Dennis Simanaitis, SimanaitisSays.com, 2026

Y’know ;
Back in the 60’s & early 70’s I used to watch those crappy C – grade Sci-Fi flicks on the grainy black & white T.V. .
Not too scary but these days I’m beginning to wonder if someone was paying attention to all those outlandish plots .
I remember one where a computer (AI) became self aware and some how impregnated a woman then locker her inside the fully computerized house until she gave birth to a baby who’s mind was that of the computer , it ended as the baby opened it’s eyes and said “I. AM. ALIVE.” .
Pretty corny right ? .
Maybe not in 2026 .
-Nate